



Dit is het vierde deel van een serie blogs over 'slimme software'. Hilbert Leijen, technisch directeur bij Infoland, geeft je hierin een uniek kijkje in onze keuken. Vorige delen gemist? Deel 1 lees je hier.
De vorige keer heb ik verteld over natural language processing, en de uitdagingen die er nog liggen bij het toepassen daarvan op de Nederlandse taal. Hoog tijd om het eens lekker concreet te gaan maken! Ik zal dat doen aan de hand van een aantal pijnpunten uit de dagelijkse praktijk van onze klanten. Wat die pijnpunten gemeen hebben, is dat de relevante informatie in belangrijke mate bestaat uit vrije tekst.
Dubbele documenten
Sommige tekst-gerelateerde vraagstukken blijken zich te laten oplossen zonder dat je überhaupt hoeft te begrijpen wát er staat. Dubbele documenten in je documentbeheersysteem is er zo een.
Het probleem zal voor velen herkenbaar zijn. Of het nu komt door fusies, onoplettendheid of onwetendheid – voor dat je het weet staat hetzelfde document op meer plaatsen in je systeem.
Als we dat kunnen tegengaan, dan voorkomen we dat eindgebruikers in verwarring raken over welk document nu het juiste, of het meest recente is. En we besparen tijd - want het is doodzonde als meerdere mensen in jouw organisatie tijd steken in het onderhouden van (bijna) hetzelfde document.
Dit vraagstuk blijk je prima te kunnen oplossen door ieder stuk tekst te beschouwen als een verzameling woorden, en die verzamelingen vervolgens met elkaar te vergelijken. Je hoeft niet te weten wát die woorden betekenen – je kijkt enkel of ze in beide documenten voorkomen.
De uitdaging is dan vooral om dat heel snél te doen. Daarbij hebben we ons laten inspireren door het welbekende Shazam. Zij kunnen supersnel muziek herkennen, doordat ze gebruik maken van een slimme hashing-methode. Een soortgelijke methodiek passen wij nu met succes toe in onze eigen software.
Soortgelijke incidenten detecteren
Zo “gemakkelijk” is het natuurlijk niet altijd. Zo kregen we de vraag van een klant (5000+ medewerkers) of we hen konden helpen met het detecteren van sterk gelijkende (bijna-)incidenten. In een dergelijke grote organisatie is het geen uitzondering dat hetzelfde probleem zich op meerdere afdelingen manifesteert. Als dat zo is, dan wil je dat graag snel weten. Je kunt dan een betere risico-inschatting maken, en beter passende acties nemen dan wanneer er op elk van die gevallen afzonderlijk geacteerd wordt. Maar kom er maar eens achter!

We hadden in Zenya al wel een functie om vanuit één incidentmelding soortgelijke meldingen te zoeken. Die bleek echter niet meer te volstaan, zeker niet in organisaties met deze omvang.
Waarom niet? Dat kwam vooral doordat die tool enkel keek naar de ‘gesloten’ vragen op het formulier – en níet naar de vrije tekst in de incidentmelding. Naarmate het aantal meldingen opliep werden er steeds meer meldingen als ‘soortgelijk’ bestempeld. Ging je echter als mens de betreffende incidentmeldingen nalezen – vrije tekst! – dan trok je een heel andere conclusie.
We moeten dus aan de slag met de open vragen in het formulier.
Dat zouden we natuurlijk kunnen doen op dezelfde manier als we doen bij het herkennen van dubbele documenten: tellen hoe vaak ieder woord voorkomt – en dat vergelijken.
Daar loop je echter snel vast, want iedere medewerker beschrijft een incident immers in zijn eigen bewoordingen.
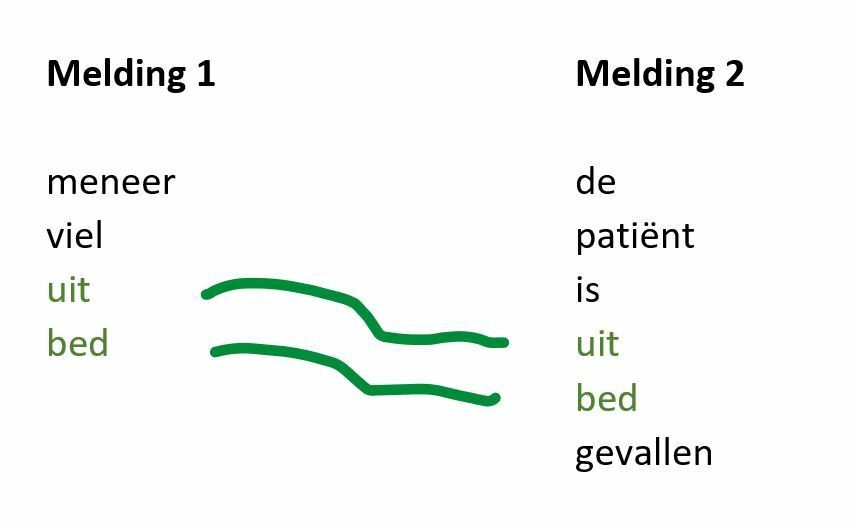
Als mens zien wij direct dat “meneer viel uit bed” en “de patiënt is uit bed gevallen” hetzelfde betekenen. Cijfermatig is de overeenkomst echter helemaal niet zo sterk – en dan is dit nog maar een heel klein stukje tekst.
Het gaat 'mis' door:
- Gebruik van verschillende woorden voor hetzelfde (soms letterlijke synoniemen, maar soms ook bredere/smallere termen zoals in dit voorbeeld)
- Vervoeging van werkwoorden
- Spelfouten
- Gebruik van (on)officiële afkortingen vs. het volledig uitgeschreven woord
We zullen dus op een slimmere manier moeten kijken naar de tekst. En dat kan je op verschillende manieren doen. Ons doel is om te kunnen bepalen welke stukken tekst inhoudelijk een grote mate van overeenkomst hebben. Een oplossingsrichting die daarbij past, is door uit ieder stuk tekst de sleutelwoorden te extraheren. De aanname daarbij is dat de teksten als geheel behoorlijk kunnen verschillen – maar dat er wel dezelfde sleutelwoorden in zullen voorkomen.

Probleem opgelost?
Nou... nee. Sleutelwoorden zijn een goed begin, maar we zullen zien dat het pas het eerste stapje is in een lange keten. Volgende keer meer daarover!