



Dit is het vijfde deel van een serie blogs over 'slimme software'. Hilbert Leijen, technisch directeur bij Infoland, geeft je hierin een uniek kijkje in onze keuken. Vorige delen gemist? Deel 1lees je hier.
In deel 4 hebben we gezien hoe sleutelwoorden ons kunnen helpen om overeenkomsten te vinden tussen (bijvoorbeeld) incidentmeldingen.
We pakken er het voorbeeld van de vorige keer weer even bij. In dit voorbeeld zien we 6 overeenkomende sleutelwoorden, en op basis daarvan kan je best stellen dat er een grote mate van overeenkomst is tussen de twee beschreven situaties.

Maar hoe komen we eigenlijk aan die sleutelwoorden?
Een geschikt algoritme hiervoor is TextRank. TextRank is gerelateerd aan het PageRank algoritme, en wat aan de basis ligt van de Google zoekmachine. In plaats van te bekijken hoe webpagina’s aan elkaar gerelateerd zijn, en op basis daarvan te bepalen wat de belangrijkste webpagina’s zijn (PageRank) – kijkt TextRank naar de opbouw van tekst – en bepaalt wat de belangrijkste woorden zijn.
Als we TextRank loslaten op onze voorbeelden, dan levert dat voor elk stuk tekst een verzameling sleutelwoorden, en bij elk sleutelwoord krijgen we bovendien een score. Die score zegt iets over hoe ‘belangrijk’ het sleutelwoord is binnen dít stuk tekst. Zeker bij kortere stukken tekst (zoals meldingen van een incident, klacht of storing) moet je van die scores echter geen wonderen verwachten.
Laat je het algoritme bijvoorbeeld los op nieuwsartikelen, dan gaat het beter. Je ziet dan de hoogste scores bij de woorden die je zelf (als mens) ook zou noemen na het artikel te hebben gelezen.
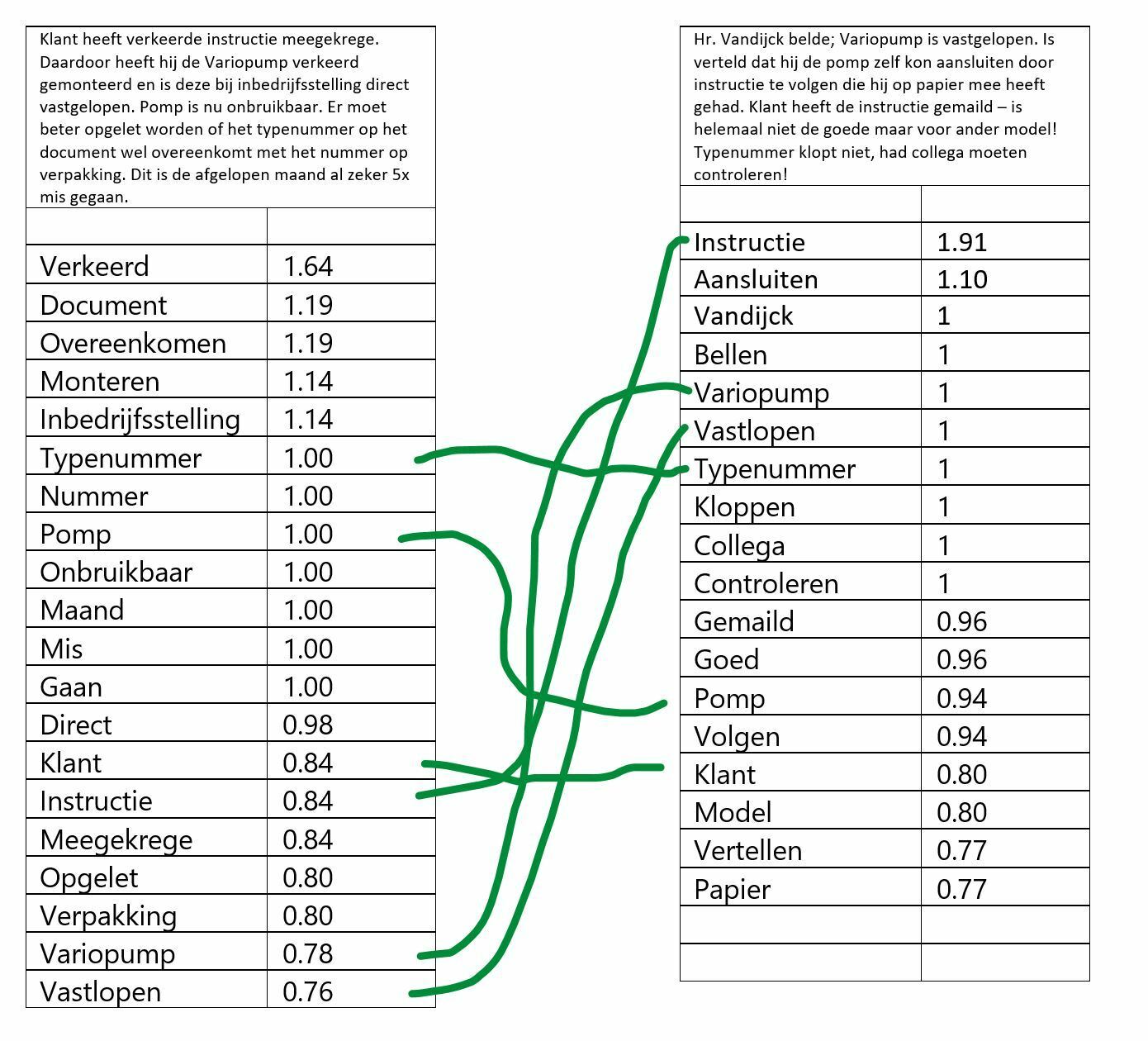
Dat zien we direct terug in onze voorbeelden. We zien dezelfde 6 overeenkomende woorden als in het eerdere plaatje. Maar als we kijken naar de TextRank scores, dan zien we grote verschillen.
“Instructie” is in de ene beschrijving een heel veelzeggend sleutelwoord – en in het andere helemaal niet.
Is dat erg?
Dat hangt af van wat je wil bereiken. Voor ons doel – de overeenkomsten vinden in incidentmeldingen – lijkt het beter om niet al te veel waarde te hechten aan de scores.
Wat valt er nog meer op?
We zien een sleutelwoord met een spelfout erin (meegekrege).
Nu maakt dat in dit geval geen verschil – omdat dit woord überhaupt niet voorkomt in het rechter tekstje. Was dat wel het geval geweest, dan had het algoritme dit niet als match gezien, door de verkeerde spelling in de linker tekst. En dat is jammer, want het maakt onze vergelijking minder goed.
Idealiter corrigeren we spelfouten daarom automatisch vóór we op zoek gaan naar de sleutelwoorden. Dat is minder eenvoudig dan het misschien lijkt.
Iedereen zal het herkennen van zijn smartphone: autocorrectie-terwijl-je-typt werkt vaak goed – maar soms leveren verkeerde correcties héle rare resultaten op. Nu zie je het op je smartphone live gebeuren – dus je kunt nog ingrijpen. De autocorrectie die wij toepassen gebeurt echter ‘blind’. Een foutieve autocorrectie kan er dan voor zorgen dat een waardevol sleutelwoord verloren gaat.

Autocorrectie van “OK” naar “oké” klinkt onschuldig – maar in een medische setting ben je zojuist een stuk belangrijke informatie kwijtgeraakt (OK = Operatiekamer). En een te ijverige autocorrectie zou proberen om “Variopump” te vervangen door een term die wél in het Nederlandse woordenboek staat. Ook niet wenselijk.
De ultieme oplossing hebben we nog niet gevonden. We kiezen daarom vooralsnog voor een ‘veilige’ route: we passen alleen relatief eenvoudige correcties toe op verkeerd gespelde woorden die voorkomen in het woordenboek. Woorden die niet in het woordenboek staan, laten we per definitie ongemoeid.
Dit vereist overigens wel dat we weten in welke taal de tekst die we analyseren is geschreven.
Hiervoor zijn kant-en-klare technische oplossingen beschikbaar, die een redelijk betrouwbaar resultaat geven. Daarnaast kunnen we in dit geval uit de context wel afleiden wat de meest waarschijnlijke taal is (een incidentformulier wat in het Nederlands is opgesteld, zal doorgaans in het Nederlands worden ingevuld).

Er begint zich al een aardige ‘pijplijn’ te vormen.
We missen echter nog steeds een paar gereedschappen om tot de ultieme sleutelwoorden te komen.
Volgende keer meer!