



Dit is het tiende deel van een serie blogs over 'slimme software'. Hilbert Leijen, technisch directeur bij Infoland, geeft je hierin een uniek kijkje in onze keuken. Vorige delen gemist? Deel 1lees je hier.
In het afgelopen jaar heb ik je via dit blog op de hoogte gehouden van onze ontwikkelingen en experimenten op het gebied van ‘slimme software’. Bij experimenteren hoort ook evalueren:
Wat is er gelukt?
Wat is er niet gelukt?
Waarin gaan we verder investeren?
Wat is waardevol, maar kunnen we beter aan anderen overlaten?
In deel 9 hebben we gekeken naar de experimenten op het vlak van documentbeheer. In dit deel vervolgen we onze evaluatie, en kijken we naar de innovaties op het vlak van (incident)melden & analyseren.
Slimme software voor … incidentmanagement
- Trefwoordextractie
Vanuit onze overtuiging dat je veel méér inzicht uit meldingen van (bijna-)incidenten kunt halen als je je niet beperkt tot gesloten vragen, zijn we aan de slag gegaan met trefwoordextractie . We zijn nu in staat om uit iedere melding geautomatiseerd trefwoorden te destilleren. Dat is geen doel op zich, maar wel een mooi vertrekpunt voor de onderstaande toepassingen.
Is onze trefwoordextractie al ‘perfect’? Nee. De werking kan bijvoorbeeld verder worden versterkt door synoniemen als één trefwoord te behandelen.
We hebben ook bekeken hoe onze methodiek zich verhoudt tot generieke AI (specifiek: Microsoft Azure Cognitive Services). Op dit moment levert zo’n dienst zeker geen betere resultaten dan onze aanpak, in elk geval niet voor de Nederlandse taal. De ontwikkelingen gaan echter snel, en het is dan ook verstandig om periodiek te bekijken of het niet beter is om over te stappen naar zo’n generieke service.
- Verbeteren van zoekfunctionaliteit
Op trefwoord zoeken in incidentmeldingen kon altijd al, maar er was nog volop ruimte voor verbetering. Het exacte trefwoord waar je op zocht moest immers wel voorkomen in de tekst; een andere vervoeging of een spelfout kon al roet in het eten gooien.
We gebruiken nu via extractie verkregen trefwoorden om zoeksuggesties te doen, en om je ook resultaten terug te kunnen geven waarin een vervoeging of verkeerd gespelde vorm van jouw zoekwoord voorkomt. Deze verbeteringen hebben inmiddels hun weg gevonden naar onze software.
Voor de toekomst zien we nog meer potentieel in het gebruik van automatisch verkregen trefwoorden in de zoekfunctie; bijvoorbeeld voor het verbreden of verfijnen van de zoekresultaten op basis van gerelateerde trefwoorden.
- Nieuwe inzichten op basis van trefwoorden
Interactieve visualisaties op basis van trefwoorden maken het eenvoudig en aantrekkelijk om ‘op verkenning te gaan’ in het bestand van incidentmeldingen.
Een woordenwolk is een eenvoudig en doeltreffend middel dat de meest voorkomende trefwoorden (in een periode) visualiseert. Je pikt er snel uit wat de onderwerpen zijn die voor de meeste incidenten zorgen – zonder te hoeven nadenken over zoekqueries en rapporten.
Nadeel van de woordenwolk is dat bepaalde trefwoorden structureel dominant aanwezig zullen zijn. We hebben daarom gezocht naar een manier om ‘opvallende’ trefwoorden te identificeren, en ook hier een interactieve visualisatie van gemaakt. Zo ontdek je snel opkomende trends. Beide zaken zijn inmiddels al ‘geland’ in onze software.
Beperking van de huidige functionaliteit is dat deze acteert op individuele trefwoorden. Je ontdekt wellicht een trend m.b.t. een bepaald apparaat, maar het helpt je niet om trends te ontdekken als ‘apparaat X in combinatie met werkwijze Y geeft bovengemiddelde veel storingen’.
- Automatisch correlaties detecteren
Daarom zijn we aan de slag gegaan met het herkennen van correlaties. We hebben ons hier in eerste instantie beperkt tot correlaties tussen gesloten vragen.
Praktijktests wijzen uit dát je op basis daarvan correlaties kunt opsporen en visualiseren. Bijvoorbeeld (in een zorginstelling) een correlatie tussen het aantal valincidenten en de afdeling waarop die plaatsvinden (geriatrie), of het moment van de dag (’s nachts meer valincidenten).
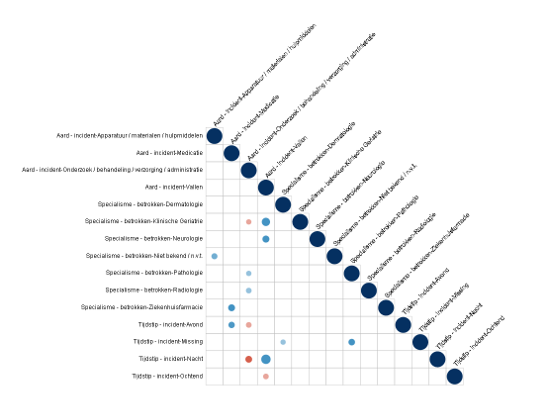
Technisch correcte resultaten dus, maar ze leveren bepaald geen vernieuwende inzichten.
We hebben dit spoor daarom geparkeerd.
- Automatisch clusters van sterk gelijkende meldingen detecteren
Aanleiding voor dit vraagstuk was een probleemstelling uit de praktijk van het Amsterdam UMC. Op jaarbasis worden er duizenden (bijna-)incidenten geregistreerd, waarvan een groot deel decentraal in de organisatie wordt afgehandeld.
Uitdaging is dan om op centraal niveau toch een goed beeld te krijgen van wat er speelt. Als soortgelijke incidenten zich beginnen voor te doen op meerdere afdelingen (zonder dat ze dat van elkaar weten) – dan wil je dat op afdelingsoverstijgend niveau snel weten, zodat je een goede risico-inschatting kunt maken en maatregelen kunt nemen die horen bij de werkelijke omvang van het probleem.
De huidige indeling van de (bijna-)incidenten in een tiental categorieën waaronder “Anders” leverde enkel globale trendinformatie.
Om dit te doorbreken hebben we gewerkt aan een model voor het automatisch vergelijken van meldingen met elkaar, om vervolgens de sterkst gelijkende meldingen te clusteren. Resultaat van dit model: een maandelijkse rapportage met gevonden clusters – met de potentie om hier ook de ontwikkeling van die clusters door de tijd heen aan toe te voegen.
Daarmee zou je op centraal niveau veel efficiënter te werk kunnen gaan en gerichte aanbevelingen kunnen doen naar de organisatie zonder dat je grote hoeveelheden (bijna-)incidenten moet doornemen om zelf de trends eruit te destilleren.
Conclusie na een aantal maanden proefdraaien in het Amsterdam UMC en twee andere ziekenhuizen? Een aansprekende belofte – maar de bereikte resultaten zijn nog niet goed genoeg om er in de praktijk op te kunnen bouwen. De techniek identificeert daadwerkelijk clusters – maar de gevonden clusters bevatten nog teveel ruis. Daarnaast blijft er nog teveel onder de radar – clusters waarvan ervaringsdeskundigen wéten dat ze bestaan komen toch niet altijd boven in de rapportage.
Tot uitrol in de praktijk is het dus nog niet gekomen. We zien zeker mogelijkheden om de werking verder te verbeteren – maar tegelijkertijd is moeilijk te voorspellen of we daarmee op het gewenste niveau zouden kunnen uitkomen.
En hoe nu verder?
Het team wat begin 2019 is opgericht, is na 10 maanden van intensieve R&D ontbonden. Maar daarmee is het verhaal niet uit. We hebben veel inspiratie opgedaan, en hebben die voor een deel al kunnen verzilveren in de vorm van proof-of-concepts of zelfs productie-software.
We hebben ook verkend waar onze kracht en onze grenzen liggen. Op basis daarvan kunnen we in de toekomst betere keuzes maken: wanneer ontwikkelen we zelf, en wanneer kunnen we beter meeliften op de schouders (AI-superkrachten) van anderen?

Op dit moment werken we hard aan de roadmap voor onze software voor 2020 en verder.
Daarin gaan elementen die het ‘slimme software team’ afgelopen jaar verkend heeft zeker terugkeren.
Wordt vervolgd dus!