



Dit is het zevende deel van een serie blogs over 'slimme software'. Hilbert Leijen, technisch directeur bij Infoland, geeft je hierin een uniek kijkje in onze keuken. Vorige delen gemist? Deel 1lees je hier.
Voor de zomerstop introduceerde ik al even deze probleemstelling:
“van een klant (5000+ medewerkers) kregen we de vraag of we hen konden helpen met het detecteren van sterk gelijkende (bijna-)incidenten. In een dergelijke grote organisatie is het geen uitzondering dat hetzelfde probleem zich op meerdere afdelingen manifesteert. Als dat zo is, dan wil je dat graag snel weten. Je kunt dan een betere risico-inschatting maken, en beter passende acties nemen dan wanneer er op elk van die gevallen afzonderlijk geacteerd wordt. Maar kom er maar eens achter!”
We concludeerden al, dat het opsporen van sterk gelijkende incidenten onmogelijk is als je je beperkt tot de gesloten vragen op het incidentformulier. Om tot echt goede gelijke paren te komen, moeten we ook de mate van overeenkomst in vrije tekst kunnen vaststellen. Dat kunnen we doen door het extraheren van sleutelwoorden uit die tekst
En daarmee hebben we de data die we nodig hebben om naar gelijkenissen te gaan zoeken. De uitdaging die rest is echter om dat heel efficiënt te doen.

Onder de motorkap van Zenya zit een relationele database. Die is supergoed in het snel beantwoorden van vragen als ‘geef me alle meldingen die zijn ingevoerd tussen 3 februari en 18 februari’, of ‘geef me alle meldingen met status ‘Geaccepteerd’ en eigenaar ‘Hilbert’.
Als we in die database vertrekkend vanuit één specifieke melding alle gelijken willen vinden, dan kan dat met een zoekvraag zoals (in pseudo-code)
SELECTEER (meldingsnummer) UIT ALLE MELDINGEN WAARVOOR GELDT: Afdeling = Afdeling huidige melding EN Aard incident = Aard incident huidige melding EN Dag van de week = Dag van de week huidige melding EN Sleutelwoord 1 KOMT VOOR IN Sleutelwoorden huidige melding EN Sleutelwoord 2 KOMT VOOR IN Sleutelwoorden huidige melding ...
Dat wordt snel complex, en wie goed oplet, ziet dat bovenstaande query alleen exacte matches zal teruggeven. En dat is niet wat we willen.
We willen immers graag weten dat dezelfde situatie zich heeft voorgedaan, op verschillende afdelingen. Of op een verschillend tijdstip. Of allebei. En de sleutelwoorden bij de meldingen zullen overeenkomsten moeten hebben, maar zullen zelden 100 procent gelijk zijn. We hebben dus een nog veel complexere query nodig. Het opsporen van de min of meer gelijken, vertrekkend vanuit één melding, is in een relationele database dus een hele opgave.
Maar om het probleem van de klant op te lossen moeten we nog een stap verder. Je wéét niet waar de setjes gelijke meldingen zitten. Als je bovenstaande complexe query lukraak moet gaan toepassen op iedere melding – totdat je per toeval een setje gelijke meldingen tegenkomt – dan ben je wel even bezig.
We hebben dus andere database-technologie nodig, en hebben die gevonden in de vorm van een graph database. Een graph database blinkt uit in het efficiënt opslaan en bevragen van netwerkstructuren.
Daarbij moet je niet direct denken aan Wifi enzo, maar aan sociale netwerken als Facebook.
In zo’n netwerk zijn allerlei entiteiten op allerlei manieren met elkaar verbonden:
Hans is bevriend met Esther; Esther is de dochter van Marie; Marie is lid van de ‘weggeefgroep Valkenswaard’; Esther wordt gevolgd door Willem; Willem vindt de laatste film van Quentin Tarantino leuk; Harrie vindt die film ook leuk; enzovoorts.
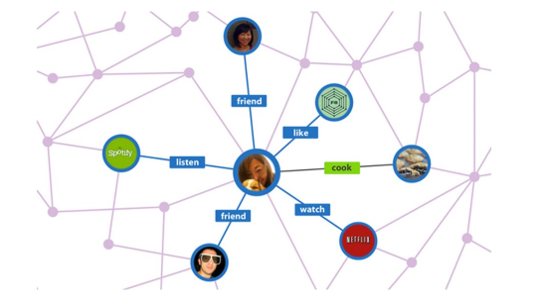
Het verschil met een relationele database wordt het meest zichtbaar bij een zoekvraag waarvoor je véél verbindingen moet volgen. Bijvoorbeeld:
“geef me alle muziekalbums die leuk gevonden worden door mensen die houden van films in hetzelfde genre als ‘Pulp fiction’”.
Waar een relationele database het dan relatief snel zwaar krijgt, blijft de graph database ook bij enorme hoeveelheden data prima in staat om je snel het juiste antwoord te geven.
We hebben dus alle incidentmeldingen in een graph database geladen. Je kunt ze dan opeens visualiseren als een netwerk van nodes die met elkaar in verbinding staan: incidenten delen met elkaar de afdeling waarop ze plaatsvonden, de aard van het incident, de dag van de week, een specifiek sleutelwoord enzovoorts.
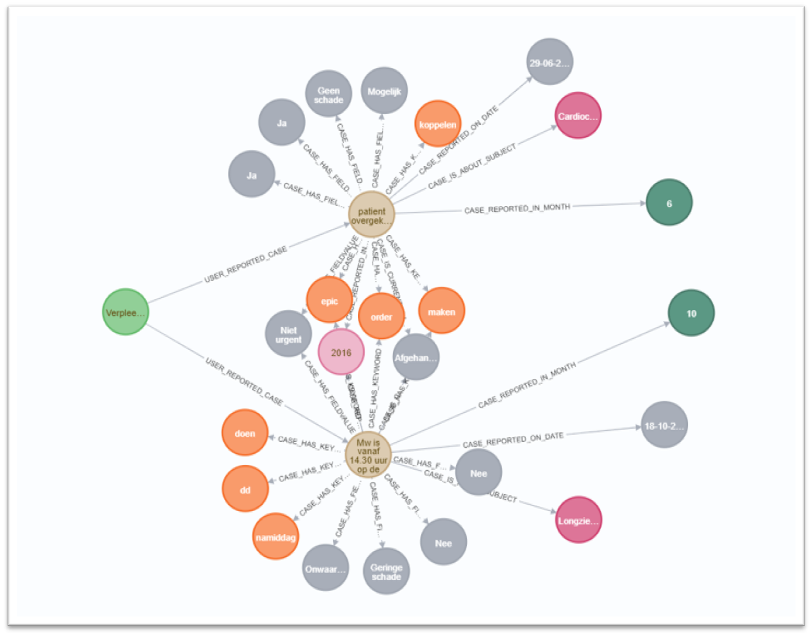
Binnen de graph database maken we gebruik van slimme algoritmes voor community detection. Community detection is een techniek voor het opsporen van ‘gemeenschappen’ (maar je mag het ook ‘clusters’ of ‘trosjes’ noemen) entiteiten in een netwerk. Entiteiten vormen een ‘gemeenschap’ omdat ze bovengemiddeld veel overeenkomsten met elkaar hebben.
Met het juiste algoritme, en de juiste parameters zou je dan vervolgens uit dat hele grote netwerk een heel simpel lijstje moeten kunnen verkrijgen. Een lijstje van setjes meldingen die volgens het systeem héél erg hetzelfde zijn. Vervolgens is het dan weer aan de mens (in dit geval: de centrale incidentmeldingen commissie) om die setjes te bekijken, te bepalen of er écht sprake is van een zich herhalend probleem, en passende actie te ondernemen.
De huidige status?
Op dit moment hebben we een werkend proof-of-concept operationeel. In samenwerking met de klant die het probleem bij ons aankaartte, zullen we de komende maanden toetsen hoe goed de resultaten van dit systeem echt zijn, en waar nodig finetunen.
Hopelijk kunnen we eind dit jaar concluderen dat we iets moois neergezet hebben. De volgende uitdaging is dan om te bedenken hoe we deze innovatieve technologie voor álle klanten beschikbaar kunnen maken.
Wil je meer weten over graph databases versus relationele databases? Lees dit blog van Neo4j. Neo4j is de leverancier van de graph database die wij momenteel gebruiken voor ons proof-of-concept.
Voor meer nieuws uit onze keuken, lees snel verder in deel 8!